目前在个人的理解中, 在存储高带宽需求场景下, RDMA的RoCEv2方案, 在节省CPU, 使CPU用在提供更高的IOPS的处理能力上, 是显著优势了.
在不超过40Gbps的场景下, TCP还是可以用的. 按之前收集的论文数据, 大概是RDMA下, 1%的CPU消耗对比, TCP时100%+的CPU消耗, 在100Gbps以上时, CPU消耗10多个核, 对于主流服务器CPU单C超线程完也才32核, 在那个量级下, TCP从成本上基本完全不可用了. 内存带宽, TCP存在成倍的内核<->用户态复制的开销, 在现在的内存通道情况下是没达到瓶颈, 但是也挺浪费. 虽然也有提到TCP spice方案, 但论文中觉得不是长期方案.
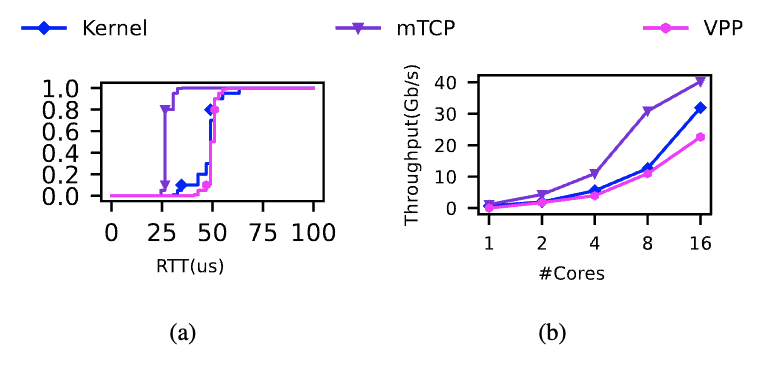
从下图可以看出,内核 TCP 的性能远未达到我们的 SLO。具体来说,图 2(a)表明内核 TCP 的基本 RPC 延迟中位数已经达到 50μs。相比之下,我们的高性能类 EBS 要求端到端响应延迟为 100μs[3]。图 2(b)进一步显示,单核上的内核网络堆栈只能提供最多 600Mbps 的吞吐量。此外,图 2(b)还表明,通过分配更多核心无法解决内核 TCP 的性能问题。可能的原因之一是随着 CPU 核心数量的增加,内核开销——如跨核竞争——也会增加。
DPDK则目前处在两者中间的感觉, 转换到用户态确实能节省一部分TCP协议自身的CPU损耗, 但是相比CPU压力卸载走来说, 就没什么优势了. 兼容性视角, 当然优势还是比较大的. 只不过在存储内网下, 无法与RDMA相提并论.
TCP 仍然是许多现代大规模数据中心的核心协议。然而,随着硬件(例如,100Gbps 链路速度网络)和软件(例如,Intel DPDK 支持)性能要求的不断提高,基于内核的 TCP 堆栈已不再是一个理想的选择。在过去十年中,多个机构提出了各种用户堆栈 TCP 堆栈,提供与传统 TCP 支持相比具有显著性能改进的功能。不幸的是,我们发现这些提案在实际应用中可能无法很好地工作,尤其是在大规模部署时。
在本文中,我们介绍了 Luna,这是一种广泛部署在阿里云上的用户空间 TCP 堆栈。我们详细阐述了设计权衡,强调了线程、内存和流量模型中的三个独特特征。此外,我们分享了从现场部署中学到的经验教训。广泛的微基准评估和从生产系统收集的性能统计数据表明,L 在吞吐量方面比内核和其他用户空间解决方案高出 3.5 倍,并将延迟降低 53%。
看到本文时, 主要在内核与用户态方案的路径上, 有了以下的问题
- 从上述定位视角, 阿里的这套方案, 是否落地在了盘古引擎层?
还是哪个层级?
- 阿里的这套方案, 是否落地在了盘古引擎层? 还是哪个层级?
- 与RDMA RoCEv2的方案相比, 定位的差异, 是主打利旧硬件场景? 还是彻底PK的场景? 毕竟如果还是在用户态, 那就是和DPDK范畴相近的, CPU消耗还是不能卸载到网卡上去.
- 还是说引入新硬件? 在RDMA网卡之外提供了其他的能力?
- 结论: 定位在计算侧->存储端 中间的链路, 在计算客户端->块存储/对象存储/表格存储网关前 这条链路由于计算侧可能跨数据中心, 中间的链路就目前互联网状态, 无法使用RDMA, 因此需要在保障通用硬件兼容性的情况下, 提供高吞吐能力.
按照引文, 主要实现目标如下
- 业务核心价值: 针对目前整套的计算段->存储端的复杂网络架构下, 支持利旧硬件的情况下, 在相对CPU利用率较高的效果下可以让4K,512B等小IO跑满40Gbps-100Gbps的网卡, 相比之前的TCP吞吐量呈至多3.5倍的提升, 延时呈53%的降低. 而针对更高100Gbps等, 会引入类似RDMA硬件卸载CPU的DPU硬件, 来配合将CPU消耗等进一步优化.
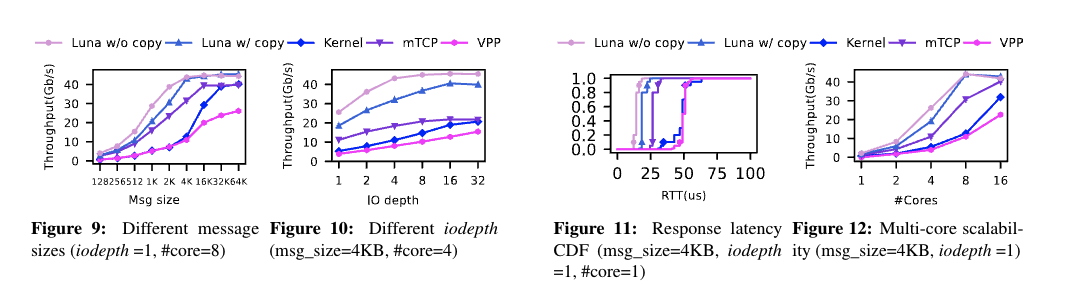
在本文中,我们讨论了 LUNA 可以有效地利用 50Gpbs NIC。但是,对于更高的带宽(例如,200 到 400Gbps),LUNA 的运行到完成与浅缓冲区可能会导致 NIC 队列溢出和数据包丢弃。此外,当消息大小为 4KB 时,LUNA 至少需要 8 个内核才能使 100Gbps 网络带宽饱和。因此,为了采用高链接速度网络,我们认为利用硬件加速是必要的。此外,虽然 TCP 可以通过多路径 TCP 使用多路径传输,但 TCP 中的队头阻塞问题及其在故障恢复方面的限制仍然促使我们专门为高性能云存储设计了一种新协议。我们最近的工作称为 Solar [29],它涉及使用与 DPU 共同设计的新传输层协议,这说明了这一点。
- 内部价值:
- 提高单核CPU可提供的吞吐量
- 解决TCP内存拷贝
- 解决TCP硬件中断多, 上下文切换多问题
- 降低TCP目前的长尾延时
- 支持跨可用区网络通信
- 对内存带宽的消耗放大减少
- 利旧, 新程序兼容旧服务器, 使其网卡同时响应传统TCP请求, 和本次新的流量
- 提高单核CPU可提供的吞吐量
主要对比mTCP和IX, 如果不是公有云这种规模, 私有云场景按照这个对比, 可能基于mTCP和IX开发是个可行方案. 不过, 如果广域网的RDMA方案出来, 且成本下降到可接受时, 可能还是以RDMA为主流方案了.
主要核心技术
- 用户态Luna替换TCP
- TCP 堆栈。如第 3 节所述,LUNA 使用 TCP 作为传输层协议。LUNA 根据 RFC
实现 TCP [2801234],并支持拥塞控制、流量控制、RTT 估计和 SACK。
- 类比xsky的RDMA的ECN拥塞控制等.
- TCP 堆栈。如第 3 节所述,LUNA 使用 TCP 作为传输层协议。LUNA 根据 RFC
实现 TCP [2801234],并支持拥塞控制、流量控制、RTT 估计和 SACK。
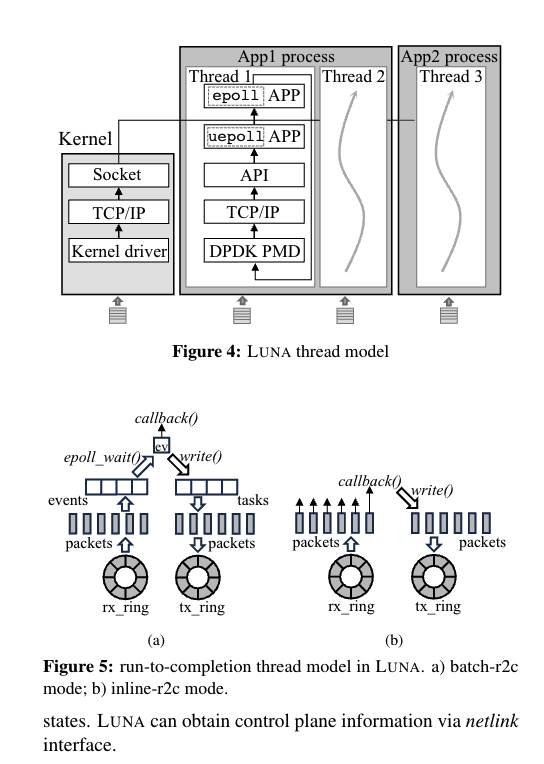
- LibOS模式运行
- 在此设置中,应用程序和 LUNA 在同一进程中运行并共享内存地址空间。或者,可以在单独的进程中运行网络堆栈,并通过共享内存进行通信.在这种情况下,如果每个服务器中只有一个网络进程来服务于不同的应用程序进程,则称为微内核模式(例如,Google Snap [27])。另一种解决方案是为每个应用程序进程设置一个网络堆栈进程,称为 Sidecar 模式。
- 参考Irene Y.
Zhang: 高层次内核绕过 I/O 抽象的案例 --- Irene Y. Zhang: The Case for a
High-level Kernel-Bypass I/O Abstraction 可知, 如果缺失该环节,
DPDK和RDMA均需要单独实现拥塞控制和流量控制, 在该环节, 则可进行一层抽象
- 提供易用性
- 提供可迁移性
- 提供灵活性
- 线程间 share nothing架构
- run to complete模型
- inline run to complete
- LUNA 也逐个处理数据包。但是,LUNA 避免将事件添加到事件队列中,而是立即调用已注册的回调函数,生成响应以及数据包的协议标头,然后将它们发送出去。简而言之,inline-r2c 将处理每个数据包直到完成。
- 显然,inline-r2c 消除了事件入队和出队的开销,并提高了缓存局部性,从而提供了更好的性能。但是,inline-r2c 还需要一个新的编程模型,并强制 upperlayer 应用程序使用类似 raw-packet 的零拷贝读 / 写接口。此外,inline-r2c 仅在 LibOS 模型中可用,因为应用层代码必须与网络堆栈位于同一位置
- 一般类比应该是用在高优先级请求上, 确保该请求的低延时
- batch run to complete
- LUNA 通过 TCP/IP 堆栈一次处理一个接收到的数据包,然后为每个具有 TCP 有效负载的数据包向事件队列添加一个读取事件。在 LUNA 处理完本轮收到的所有数据包后,应用程序将立即处理这些读取事件。然后,RPC 框架调用注册到每个事件的回调函数,生成响应消息,并将消息发送到发送缓冲区。处理完所有事件后,LUNA 会在发送缓冲区中添加消息的协议标头,将它们转发到 NIC,然后开始下一轮。
- batch-r2c 工作在更传统的类似 epoll 或类似 libev 的编程模型中,并且与传统的类似 BSD-Socket 的接口兼容。在实践中,我们在 EBS 等面向性能的服务上部署 inline-r2c,出于兼容性考虑,我们将 batch-r2c 用于对象存储等服务。
- 一般类比应该是用在正常优先级请求上, 确保整体延时保障
- inline run to complete
- run to complete模型
- 内存 零拷贝
- LUNA 在接收端和发送端支持完整的数据路径零拷贝缓冲区,旨在最大限度地减少数据移动开销。LUNA 在用户空间 slab 子系统的帮助下实现了其全栈零拷贝。此子系统引入的开销很小,并维护传统的编程模型。
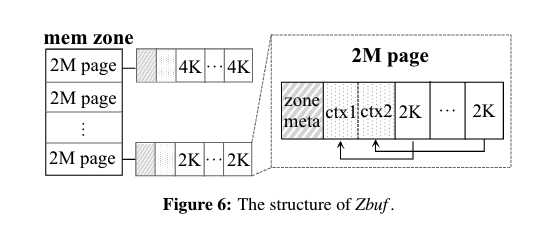
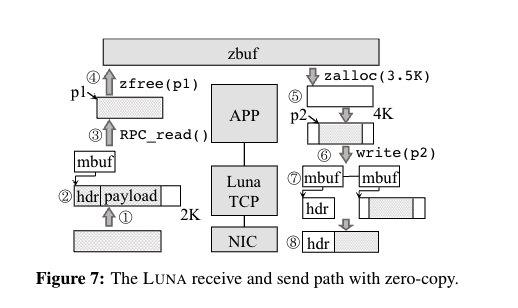
- Zbuf
- 用户空间 slab 子系统。Zbuf 用作用户空间 slab 子系统,为用户预先分配内存块。图 6 显示了 Zbuf 的结构。我们可以看到 Zbuf 保留了从 DPDK 的内存地址空间分配的几个大页面,并将它们划分为多个 2MB 的内存区域。每个内存区域的标头记录元信息,例如物理地址。内存区进一步拆分为 OBJS,OBJ 可以直接由户(即应用程序)。objs 的元数据(在图 6 中表示为 ctx)与 objs 位于同一内存区中,紧跟在区域元数据之后。同一内存区中的所有 obj 共享相同的大小,但大小可能因内存区而异(例如,图 6 中的 2KB 与 4KB)。Obj 生命周期管理。Zbuf 使用引用计数器来管理每个 obj 的生命周期。初始化后,计数器设置为 1。之后,每当复制相应的 obj 时,计数器就会增加 1,每次释放 obj 时,计数器就会减少 1。一旦计数达到 0,obj 将被放回内存区的空闲列表。
- DMA
- 通过 DMA 将数据包数据发送到 OBJ ((1))。网络堆栈使用网络协议 ((2)) 处理数据包,并将指向可读有效载荷的指针(在图 7 中标记为 )通过 RPC 接口 ((3)) 传送到上层应用程序。应用程序可以在完成消息处理后直接释放有效负载 ((4))。Zbuf 将找到相关的 obj 并通过减少引用计数来释放它。
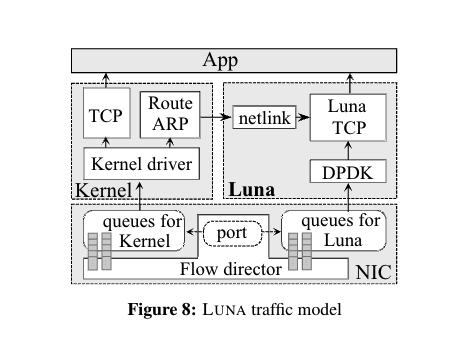
- 流量模型
- NIC 多队列区分 内核/用户空间流量
- 将控制平面(即 ARP 表和路由表管理)留给内核,并使用 netlink
接口访问路由信息。
- LUNA 使用 Flow Bifurcation 和 SR-IOV
支持,为用户空间流量保留一定的端口范围,这样就不会干扰内核流量。内核网络堆栈直接处理
ARP 请求和响应等控制平面消息,并管理控制平面
- Flow Bifurcation
- SR-IOV 支持
- LUNA 使用 Flow Bifurcation 和 SR-IOV
支持,为用户空间流量保留一定的端口范围,这样就不会干扰内核流量。内核网络堆栈直接处理
ARP 请求和响应等控制平面消息,并管理控制平面
- DPDK轮询 用户空间流量
- PMD轮询模式驱动程序
- 巨页管理
- 数据结构
- 哈希映射
- mbuf
总结
大体上, 阿里这套方案在存算分离架构下的私有云的IaaS中, 计算侧网络可借鉴, 只不过工作量角度, 可能大幅复用DPDK/IX等方案, 存储侧走RDMA毋庸置疑. 对于如果没有此类复杂网络场景, 在具体核算成本TCO时, 也许有可能还是全套RDMA方案划得来?