理解
大家最受影响的就是一半时间开发, 一半时间运维的这个问题. 利用一个成熟的配置文件, 快速部署起自己需要的环境, 而不是一步步通过页面控制点击, 这是一个很省力的事情. 将运维中与部署相关的事情通过一些成熟的模板化的配置文件来提供, 最好不过了.
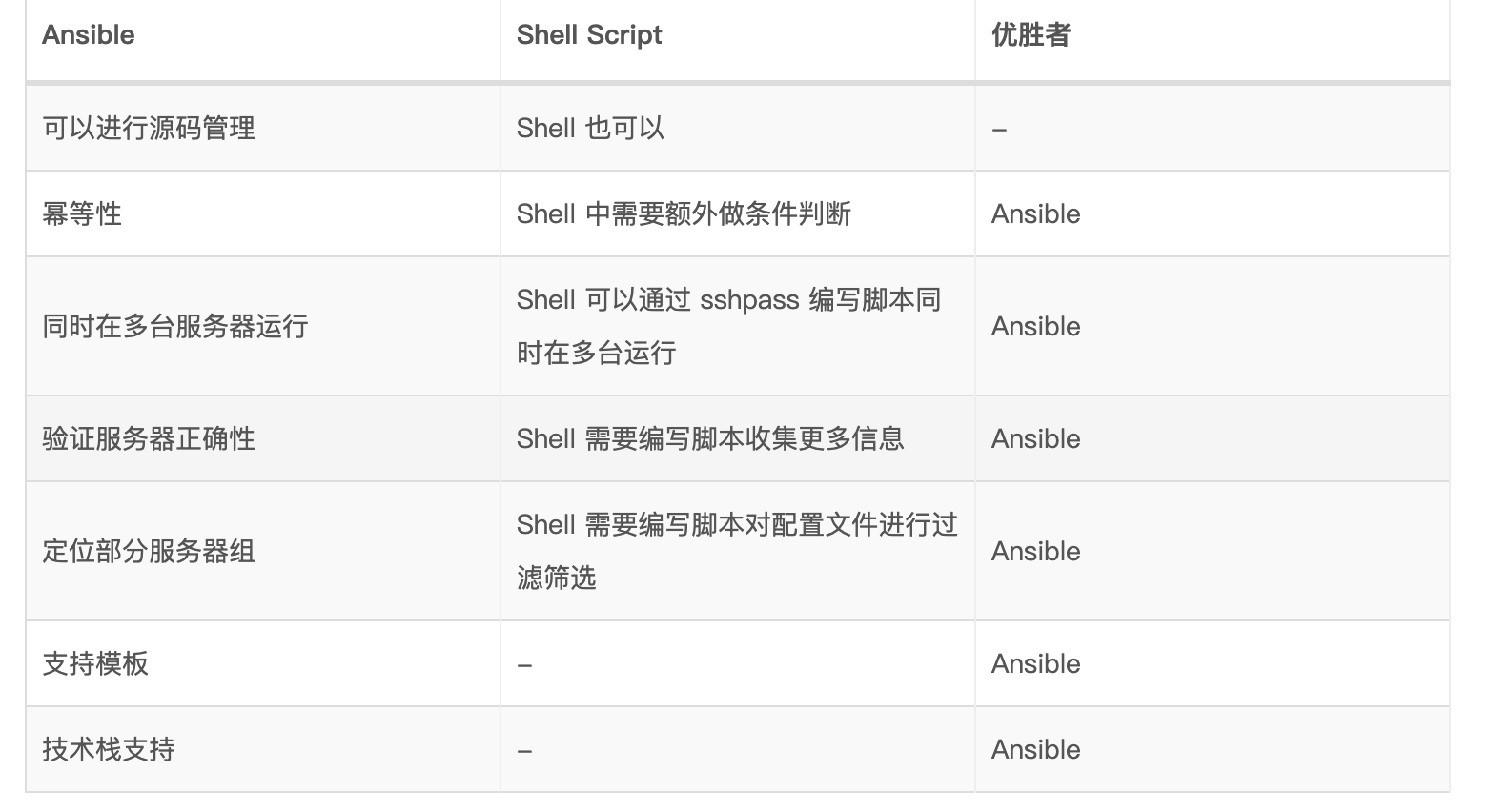
ansible比较大的几个优点
- 由于是开源框架, 基于ansible的针对其他开源软件的配套代价较多
- 比如集成钉钉等
- 配置文件化管理部署成熟
- 可针对不同的环境, 使用不同的配置文件快速部署
- 可以使用开源插件快捷对接配置管理服务
- 因为 Ansible2.0以上的版本已经原生集成了consule: consul_module
不建议的操作
建议遵循unix思想, 一个工具只做该做的事情,
ansible虽然提供了能力, 但是能由脚本来完成的事情,
没必要在ansible中进行处理
根据[^10]终于意识到我现在所处理的最别扭的地方在哪里了...这篇文章中说了下述几点.
- 在 ansible 中使用复杂的语法规则
- 更推荐直接封装成脚本, 由脚本来进行这些操作.但是脚本的粒度拆分, 什么应该让ansible来操作, 什么应该让脚本来处理, 是个边界.
- 明明几行 Shell 就可以搞定的事情,为什么一定要使用 Ansible 来做呢?
- 明明一个 Shell 脚本就可以完成的环境监察,为什么一定要使用 Ansible Playbook 来做呢?要知道 Playbook 编写语法虽然是 YAML,但是使用起来并不简单,有很多特殊的语法需要去注意,完全没有必要花费精力去学习一个新的工具去完成。
- 如果脚本中存在较多判断,不宜使用 Playbook 实现逻辑
- 如果脚本中存在部分参数解析功能,不宜使用 Playbook 实现逻辑
- 不要过度拆分 task,保证每个 task 完整性
从个人使用上来说,Ansible 还是很好用的,至少它无需 Agent,SSH 连接等特性,使用起来很友好。
但是我们也不应该过分使用 Playbook,编写 Playbook 解析 json 花费了不少的时间,远不如直接在被执行脚本中完成的成本低。
tidb开发计划
deploy.yml 用来部署集群。执行 deploy 操作会自动将配置文件、binary 等分发到对应的节点上;如果是已经存在的集群,执行时会对比配置文件、binary 等信息,如果有变更就会覆盖原来的文件并且将原来的文件备份到 backup(默认) 目录。
start.yml 用来启动集群。注意:这个操作只是 start 集群,不会对配置等信息做任何更改
stop.yml 用来停止集群。与 start 一样,不会对配置等做任何修改。
rolling_update.yml 用来逐个更新集群内的节点。此操作会按 PD、TiKV、TiDB 的顺序以 1 并发对集群内的节点逐个做 stop → deploy → start 操作,其中对 PD 和 TiKV 操作时会先迁移掉 leader,将对集群的影响降到最低。一般用来对集群做配置更新或者升级。
rolling_update_monitor.yml 用来逐个更新监控组件,与 rolling_update.yml 功能一样,面向的组件有区别。
unsafe_cleanup.yml 用来清掉整个集群。这个操作会先将整个集群停掉服务,然后删除掉相关的目录,操作不可逆,需要谨慎。
unsafe_cleanup_data.yml 用来清理掉 PD、TiKV、TiDB 的数据。执行时会先将对应服务停止,然后再清理数据,操作不可逆,需要谨慎。这个操作不涉及监控。
并行任务引擎
作业编排:可以自由选择相应的原子化操作,编排和发布新的作业流程
可视化: 通过拖拽鼠标编排作业流程和参数表单,作业运行与任务的状态可视化
并行调度: 同一个作业中的任务支持并行执行,在很多场景下能极大的缩短执行时间
实时监控: 任务的运行状态在页面上实时更新
断点执行: 执行错误的任务在修复错误后可以继续执行,不需要重新执行整个作业
任务回滚: 遇到错误,可以支持回滚作业中已经执行过的任务,恢复执行环境
作业模板: 可定制作业模板,用模板创建作业实例,避免重复工作
任务组: 在作业模板中把任务分组,在创建任务实例时候可以动态的复制任务组,相似的作业使用同样的模板,但又不限制于模板
计算表达式: 使用表达式动态的计算任务的参数值,能够极大的简化重复参数的输入以及复杂参数的拼接
动态参数:前面任务的输出作为后续任务的输入参数
同类比较
- fabric
- 快速入门使用
- puppet
- C/S架构
- 大部分付费功能
- Chef
- ansible
- 语义多层架构
- 基于ssh, push/pull均支持
- cephadm是使用工具的配置语法进行部署后,
为了更强程度的自定义而进阶开发的产物.
- TODO:设计角度, 为什么cephadm用了docker?
- 另外, cephadm支持所有业务的部署能力是否和这个有关?
- SaltStack
- 基于python的开源CM工具
- CS架构
- 学习曲线低
- cephadm之后有配套saltstack的
- Kolla-ansible?
- 应该是openstack用的
- 苏宁的产品化Hull思路
- 基于上面的, 设计标准的RESTAPI
- 定义Workflow
- 可视化安装
- 增加Data Center, cluster, region等逻辑概念, 更好的满足用户的部署需求.
遵循的设计模式理念
- 开闭原则
- 将分配策略, osd与故障域拓扑的关联, 更改为基于osd的属性进行策略分配, 策略为可扩展
- 借助ansible, 使各个团队之间的组件, 仅基于yaml的定义进行插拔, 配置文件存在对应key, 触发对应的role. 且各个模块上下文之间存在公用属性, 直接从基础变量中加载. 扁平化传递, 无需封装.
最佳实践
重试逻辑
--start-at-task
这里采用的方案是自定义一个callback的插件,
将failed的task记录下来,见callback, 然后封装一个CLI,
在下次执行的时候增加--start-at-task {task_name}来进行调度.
### 优化方案 和一开始调研时的目的有点不一样,
现在发现的主要问题在于ansible做的预处理的逻辑太多了,
而且主要框架严重依赖单独的ssd和shell,
这样带来的问题你就是部署的性能较差.
需要找一些优化的方案
- facts收集
- 关闭
- 设置缓存
- 增加并发
- 修改运行策略为free等.
- ssd长连接
- 开启pipelining.
- 原本的逻辑是将library,role等生成一个脚本, 复制到远程主机上, 再执行. 现在改为通过pipe直接传递给ssh会话.
- 开启accelerate模式, 是需要对面的远程服务, 预计是通过rpc类似?
- 通过poll设置一段时间后再来查询, 不阻塞着等待了.
插件开发
callback
主要目的是支持可以解析出当前失败的任务, 然后给另一个进行重试的接口进行使用.
rolling upgrade什么意思
好像应该叫做rolling update模型, 哦,滚动升级
哦, 忽然明白为什么是loop结合delegate_to了, 因为要的不是并发,而是滚动操作.
继承的方法
- v2_runner_on_failed
- runner_on_failed
这俩函数有什么区别呢? 目前看起来v2版本并没有加强多少? 那就随意使用了先.
理解开发方式
感觉[^3]这种插件的阅读方式能提供一些参考.
python调用ansible
python3.8 调用ansible 2.9.4 api | 经验分享&服务器代维
ansible使用
开源许可证
根据GPL
license implies that my plugins are also GPL (MPD's note: it does not) ·
Issue #8864 · ansible/ansible可知,
虽然ansible是GPL 3.0,
但是由于我们编写的部署脚本是被ansible读取执行, 并非链接.
因此可自行决定使用的许可证.
调试方式
- epdb
- -vvvvvv
- 虽然文档中只写了
-vvv, 但是实际上代码里有一部分写了vvvvvv的函数. - 达到这个等级的时候, library里写的logging日志就能输出了.
- 虽然文档中只写了
- 设置ANSIBLE_KEEP_REMOTTE_FILES=1, 然后再运行Ansbile命令
- ansible运行前生成的临时脚本就会保存下来, 不会被删除了.
- 有时候还是用syslog比较省事
- 其次这次说的raise Exception, 像是facts/system/distribution.py里的依旧没打印出来, 看着像是被拦截直接跳过的
Debugging modules — Ansible Documentation�
tower付费部分
- workflow?
- workflow和任务队列的区别应该在于低代码吧?
- 还是说图形界面的任务的图形化操纵叫做workflow?
练习方式
chusiang/ansible-jupyter.dockerfile: Building the Docker image with Ansible and Jupyter.
Ansible 用 Docker Compose 练习 Ansible_w3cschool
执行
通过playbook调度role的task,
来进行批量任务执行. ### workflow操作多个playbook是否有开源替代方案?
还是直接写playbook, 通过role控制. 目前来看, 不算特别关键.
语法
playbook
1 | ansible-playbook -i {inventory host} add-osd.yml |
delegate_to
这里为什么看到和loop一起使用?
delegate_to不支持直接指定组嘛?为什么要loop
这个的主要用途难道不是到一个只需要一个组内的一个节点执行的时候, 直接选中某一个吗?
ansible解析参数的过程, 和delegate_to这种指定某个节点只执行一次的逻辑, 是哪个优先呢?
如果是后者, 那是否这个的目的是用来让这个组内只在第一个节点执行一次?
但是感觉有点像是后者
1 | delegate_to: "{{ item }}" |
run_once
当我不需要指定哪个节点来执行一个集群任务的时候, 直接用run_once就可以ile,他会直接指定第一台
group_vars 自定义相对路径?
不可以, 只能是当前执行hosts所在的目录的相对路径
roles搜搜路径
可以修改ansible.cfg内的配置
shell模块指定路径
1 | name: xxx |
role
自定义模块, 内部包含具体的task
依赖管理
在 playbook 中存在多个 roles,且其中有相互依赖关系时,合理使用 meta 配置,填写其所依赖的 roles。注意,被依赖的 roles 会优先执行
include_task
在role内使用include_task无法使用start-at-task直接跳转,
而import_task可以
配合tags需注意使用apply
1 |
|
Ansible include_tasks will not run when tags are specified - Stack Overflow
ad-hoc
全节点临时执行的命令, 这个对于排查问题全节点查日志的时候还是用的比较多的.
1 | ansible 主机或组 -m command -a '模块参数' ansible参数 |
ceph-ansile
[^2]里稍微解释了一部分.
问题
根据目前的调研结果来看, 存在两个问题 * osd层无法支持用于db,wal分区之后剩余空间创建osd * crush rule无法自由指定 * 不支持tier创建 * 不支持针对ec模式下的资源池,通过创建副本的元数据资源池进行创建rbd.
二次开发问题
- 开发环境到底怎么才能部署起来呢?如果不使用实机已经装好ceph和ceph-ansible的环境, 就没有办法了?
- 为什么看vagrant.yml.sample里, 都是从一个裸机开始呢?怎么里面就不能装好ceph依赖吗?
姑且按照[^5]先启动看看.`
osism/ceph-ansible Tags - Docker Hub
vagrant 启动失败了, 似乎我用的centos景象不太一样, 找个docker hub里的试试
所以library其实完成的任务就是拼接command?
AnsibleAPI 开发 - 简书 参考上面这篇文章基本可以说明怎么使用ansible提供的库
实践中的一些疑问
command和 debug冲突?
对应的是不同的Task, 因此的确会冲突
shell和command有没有区别?
一个是启动shell, 一个是启动sh
默认ansible使用的module 是 command,这个模块并不支持 shell
变量和管道等,若想使用shell 来执行模块,请使用-m 参数指定 shell
模块,但是值得注意的是普通的命令执行模块是通过python的ssh执行。
changed 是用来标记task的幂等性满足与否?
的确, 用来标记这个任务是否对环境产生了修改?
groups保留字
属于ansible自身的保留字段
变量和inventory还是有点区别的, 虽然是这个主机组的, 但是单纯的变量其实没有主机组的概念的.
为什么ceph没有提供给ansible基于rados的接口呢?
是否是因为使用的是ssh等协议, 所以用Rados其实并不太方便? 并没有设计这个connection?如果要开发, 其实是开发一个connection机制吧?
主要用途是部署, 而在部署阶段, rados得在mon部署完毕后才能工作, 因此如果要切换connection, 还必须分阶段. 还不如直接ssh全套
You cannot register a variable, but you can set a fact (which in most use cases, including yours, will be equivalent to a variable):
1 | - set_fact: |
set_fact 是注册到hostvars , 即注册到不同的host里变量.
要使用json_query , 需要安装jmespath
ansible使用register就会被标记成changed?
为什么我用filter, 带上2个大括号就无法识别出对象了呢?
因为filter是jinja2语法, 外面需要先带上双引号. * You are using the debug: module with the option var: and this expects a variable, not a jinja2 template.
对于您的模块支持检查模式,您必须在实例化AnsibleModule对象时传递supports_check_mode = True。 当启用检查模式时,AnsibleModule.check_mode属性将计算为True。
对task进行检查模式 ### ansible的模块里打印大量内容, 即便他不显示,也会记录到warning里? 有垃圾产生?
ansible的library不允许使用print, 居然就会报错. 没有日志, 需要之后再找怎么记录日志的方式
通过logging直接往其他文件, 或者通过Syslog协议等输出是一种方案.
或者可以记录到stderr中, ansible只检查stdout是否被污染, 然后报错.
不推荐用这个library, 将来自改造都不方便.
out不能是变量? 只能是字符串?
这个还需要找一下
通过debug可以打印出Ansible_facts, 但是直接引用就一直打印不出来, 忽然脑子过了一下, 想通了, ansible_facts应该是上层概念, 对于使用的应该直接填key就可以了, 然后的确拿出来了.
字符串输出转换, 坑
{}会把字符串转换成object, 导致即便to_json了, 双引号也没了, 其他程序无法识别了.- jinja2的语法问题
- Double quotes are converted to single quotes on variable assignment if contents look like JSON · Issue #44897 · ansible/ansible
- Ansible - passing JSON string in environment to shell module - Stack Overflow
ansibleSequence是什么东西?
字典的key索引不会被Jinja2解析, 这个真的是深坑
- 感觉看了下, 这个坑很大啊...一点都不方便debug
莫名其妙的module failure
没有提示的时候, 实际上问题就是在于你的模块里用了print...
ansible 是只检测stdout是否被污染, 所以如果我把信息写到Stderr里是没问题的.
python3支持问题
我们目前用的ansible 2.6, 我指望使用python3来进行操作,
避免一些问题.
按照[^13]里提到的来说,
理论上会按照从哪个python版本安装的ansible,
就从哪个版本启动的功能.
根据[^11]发现的问题就是,
我用的2.6通过ansible.cfg中的设置, 并没能生效,
而通过-e传入的参数倒是有效.
暂时通过上层传入来覆盖下层使用的解释器
group_vars的读取时间是什么时候嗯
只会在执行role的时候去读取对应的group_vars中的变量
以上是错误的, 根据Ansible
Configuration Settings — Ansible
Documentation通过ansible.cfg里增加debug = True,
发现group_vars的load过程,
在plugins/vars/host_group_vars.py代码中,
实际上在初始化阶段, 就根据每个执行任务的节点在哪些主机组里,
把对应的group_vars目录下的主机组的配置给load了.
并不是运行阶段才进行...
怎么将当前读入的配置及收集到的facts配置导出呢
- 怎么执行Export呢?
template - Templates a file out to a remote server
- copy content output from json and a variable is not idempotent under py3 · Issue #34595 · ansible/ansible
另外, 其实我并不需要ansible原生的gather_facts, 因为他能够给出来的ip, 现在我知道一些python的原生库获取, 重点在于, 我怎么把多个节点的数据给聚合到一个节点上.
- 通过set_fact去一起设置到一个字典里?
- 我通过vars聚合完了. 有个map('extract'功能可以满足这套 Is it possible combine remote results to local a register in Ansible? - Server Fault
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19- hosts: all
vars:
uuids: |
{%- set o=[] %}
{%- for i in play_hosts %}
{%- if o.append(hostvars[i].uuid) %}
{%- endif %}
{%- endfor %}
{{ o }}
tasks:
- name: get uuids for existing cluster nodes
shell: mysql -N -B -u {{ db_user }} -p {{ db_user_password }} -e "SHOW GLOBAL STATUS LIKE 'wsrep_cluster_state_uuid';" | sed 's/\t/,/g' | cut -f2 -d','
register: maria_cluster_uuids
- set_fact:
uuid: "{{ maria_cluster_uuids.stdout }}"
- debug:
var: uuids
run_once: true
delegate_to: 127.0.0.1
vars选项的运行时间是什么时候呢? 如果我采用task, 他能在我指定task前自动运行吗?
- vars的调用时间是什么时候呢? 写个代码模拟一下?
- 目前来看, 是当用到这个变量的时候, 才会去计算
- 有没有办法把list的tuple转成dict呢?
jinja2模板导出yaml
并不能自动识别缩进. 需要自己来控制order,
使用Jinja2的filter可以完成这个步骤.
1 | pools: |
to_nice_yaml output not as expected · Issue #16707 · ansible/ansible
当我需要with_items内部针对每个循环做一个检查, 然后这个检查结果给下一个任务的每个循环使用时, 应该怎么做呢?
如果我把这个封装成一个block, 然后每个block只处理其中一个任务的时候, 这个每个循环的变量怎么穿进去呢?
比如register和with_items混用时,
是什么效果呢? 拿到的好像就是每条任务注册结果的列表.
when和with_items一起使用时,
是每次都执行一次when
好像可以利用changed这个
import_playbook可以组合多个playbook
import_playbook不支持传入指定参数.
refresh_inventory
强制重新读取inventory
1 | - name: refresh |
如何将set_fact的host级别的变量转发到其他host里
1 | - name: set fact on swarm nodes |
all.yml里的group_vars能被其他host的task读取吗?
修改hosts文件之后的refresh_inventory之后的task没有输出在日志中
根据这个(1) meta: refresh_inventory does not include previously absent hosts in task execution : ansible
和我的实际结果,
当我在多个Task中间加了一个meta: refresh_inventory之后,
后面的任务就一个都不执行了. 如果import_playbook了,
playbook倒是还会执行.
目前还没怎么看到代码, 为什么会失败.
解决方案目前是知道了, 写两个host,
上一个playbook的最后一步就是refresh_inventory,
下一个playbook再使用这个group
include_vars加载远程节点的配置 , 配合delegate_to疑问
结论, 不支持远程节点. 所以只能自己先把文件复制到本节点, 再进行导入
查找
Controlling where tasks run: delegation and local actions — Ansible Documentation
好像有remote_src选项
To assign included variables to a different host than inventory_hostname, use delegate_to and set delegate_facts=yes.
include_vars is unable to load files from remote · Issue #58169 · ansible/ansible
根据上面这篇issue可以知道,
remote_src是不准备支持的.
The error message is on a generic function, was added for users that were using actions that did allow remote_src, though clearly when added they missed the confusion possible for other actions. We should fix the error message, but i would not try to personalize it too much or we will end up with similar ticket for other actions.
同步远程节点的配置文件到指定节点 synchronize
复制文件到本地 fetch
1 | tasks: |
被跳过的任务依旧注册了变量, 导致覆盖了
ansible skipped task still register value
可以用以下方式绕过, 或者register不同名字变量,
set_fact到同一个上(set_fact支持when) 1
2register: "{{ 'real_variable' if some_condition else 'cool_story_bro' }}"
when: some_condition
gather_fact 缓存数据失效
我遇到了修改了系统的hostname, 不过在有些节点, fact结果还被缓存了, 没有重新收集的问题
在运行中重新收集可以用以下命令 1
2- name: do facts module to get latest information
setup:
我试了下,
重新创建playbook即便是同主机组好像也清理不干净,
我直接在原来的playbook里加了下述任务, 然后再注释掉重新执行就可以了.
1 | tasks: |
ansible的changed_when属性, 设置为false时, 当某个节点任务失败, 会让这个节点退出后续的任务执行?
目前是遇到这样一个问题, 直接导致后续的任务执行时节点缺失.
看概念就只是:
A boolean indicating if the task had to make changes to the target or delegated host.
dynamic playbook hosts
通过hostvars['localhost']['xxx']可以实现
Reference
- ceph-ansible 使用 | Bolog
- 干货|基于Ansible的Ceph自动化部署解析_中兴开发者社区-CSDN博客
- 第八章: 扩展ansible_个人文章 - SegmentFault 思否
- Full support for · Issue #2195 · ceph/ceph-ansible
- Easily deploy containerized Ceph daemons with Vagrant | Sébastien Han
- ansible debug模块学习笔记-行者之路-51CTO博客
- 一文搞懂 ansible 变量配置 - biglittleant - 博客园
- Ansible 面向企业大规模使用探究 – IBM Developer
- 可能是最强网工ansible入门及深入教程之 ansible杂谈 - 知乎
- Ansible最佳实践 | Yiran's Blog
- ansible/python_3_support.rst at stable-2.6 · ansible/ansible
- Interpreter Discovery — Ansible Documentation
- Wrong python2 interpreter instead of python3 · Issue #69494 · ansible/ansible
- 一些小团队的自动化运维实践经验 | 程序猿DD
- How to Manage Multistage Environments with Ansible | DigitalOcean
- 基于Ansible自研的可视化和并行自动化运维引擎 - 知乎
- Ansible 实现原理(源码分析) – Tiantian Gao ( gtt116 )